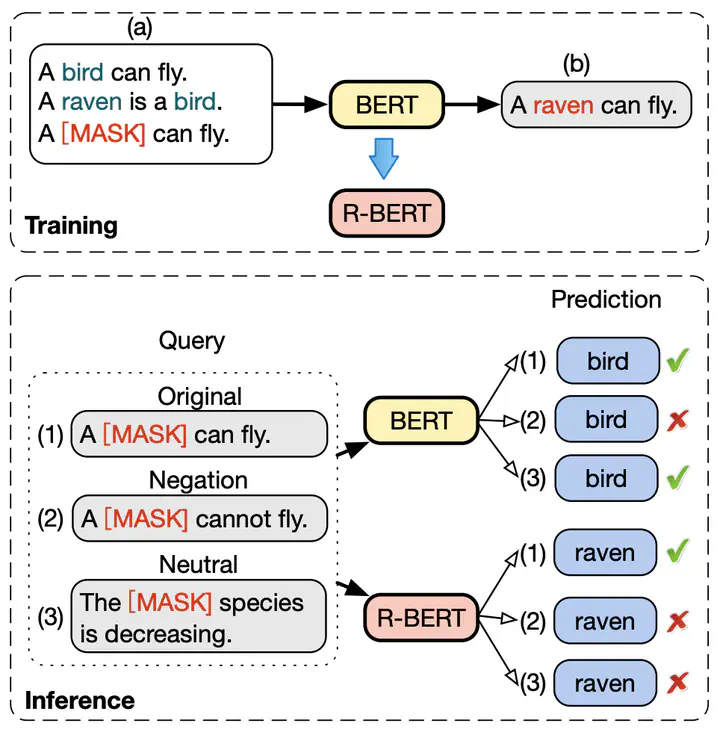
Abstract
Acquiring factual knowledge with Pretrained Language Models (PLMs) has attracted increasing attention, showing promising performance in many knowledge-intensive tasks. Their good performance has led the community to believe that the models do possess a modicum of reasoning competence rather than merely memorising the knowledge. In this paper, we conduct a comprehensive evaluation of the learnable deductive (also known as explicit) reasoning capability of PLMs. Through a series of controlled experiments, we posit two main findings. (i) PLMs inadequately generalise learned logic rules and perform inconsistently against simple adversarial surface form edits. (ii) While the deductive reasoning fine-tuning of PLMs does improve their performance on reasoning over unseen knowledge facts, it results in catastrophically forgetting the previously learnt knowledge. Our main results suggest that PLMs cannot yet perform reliable deductive reasoning, demonstrating the importance of controlled examinations and probing of PLMs’ reasoning abilities; we reach beyond (misleading) task performance, revealing that PLMs are still far from human-level reasoning capabilities, even for simple deductive tasks.