Sella - Modeling Self-evolving Collaborative LLM-based Agents
Sella: Modeling Self-evolving Collaborative LLM-based Agents
Vision
Background
Recent advancements in artificial intelligence (AI) have been significantly driven by the development of large language models (LLMs) such as GPT-4 and their effectiveness in various tasks, including dialogue generation, machine translation, question answering, and other open-ended generation tasks. LLM-based agents are AI systems that leverage the powerful language understanding capabilities of LLMs to interact with the world, make decisions, and perform tasks autonomously.
Building generally capable LLM-based agents is an active area for both academia and industry, aiming to create artificial general intelligence (AGI) systems that can handle a wide range of tasks through reasoning, planning, and tool use. By assigning different roles to multiple LLMs, LLM-based agents can form a collaborative entity for solving complex tasks, such as software development and medical diagnosis/reasoning. Several proof-of-concept demos, such as AutoGPT, LangChain, ChatDev, and MetaGPT, are inspiring examples under this vision.
Currently, single-agent systems can perform tasks such as web browsing, online shopping, and household chores. However, as task complexity increases, the limitations of single agents become apparent, particularly in handling multifaceted environments. For instance, a software development task typically involves multiple stages, including requirements gathering, design, coding, testing, deployment, and maintenance.
To address this complexity, humans have developed Standardized Operating Procedures (SOPs) across various domains, widely used to solve complex tasks collaboratively. The intricacy of these processes highlights the need for more sophisticated collaborative AI agent systems to effectively navigate and contribute to such multifaceted projects.
Collaborative LLM-based agents, which involve multiple LLM-based agents working together to solve problems, present a promising frontier. This collaboration can take various forms, such as task delegation, information sharing, and mutual reinforcement. The collective intelligence of these agents has the potential to surpass the capabilities of individual agents, leading to more robust and versatile AI systems. Recent studies have demonstrated that multi-agent collaborations yield more effective solutions for tasks requiring collaboration and communication efforts, such as software engineering and medical reasoning. By automating complex tasks across various sectors, collaborative LLM-based agents enhance efficiency and effectiveness, providing adaptable and robust solutions to meet the growing demands of modern AI applications.
Research Problem and Hypothesis
The fundamental knowledge gap addressed by this project is: “How can we enable collaborative LLM-based agents to improve their effectiveness in solving complex tasks through self-evolution?” This central research question is broken down into two key hypotheses:
- H1: The effectiveness of collaborative LLM-based agents can be efficiently assessed by automating evaluators consisting solely of multiple LLM-based agents.
- H2: The effectiveness of collaborative LLM-based agents can be enhanced through self-evolution, facilitated by the mutations of individual agents and the optimized structuring of multiple agents.
Research Objectives
To address these limitations, this project aims to develop a package of methodologies for evaluating and modeling self-evolving collaborative LLM-based agents. The project has the following three objectives:
- O1: Automating LLM agents evaluation with collaborative LLM agents.
- O2: Research and develop new methodologies that model the self-evolution of single agents and collaborative agents.
- O3: Developing a versatile simulation platform for the self-evolution of collaborative LLM agents.
Approach
Work Packages (WPs)
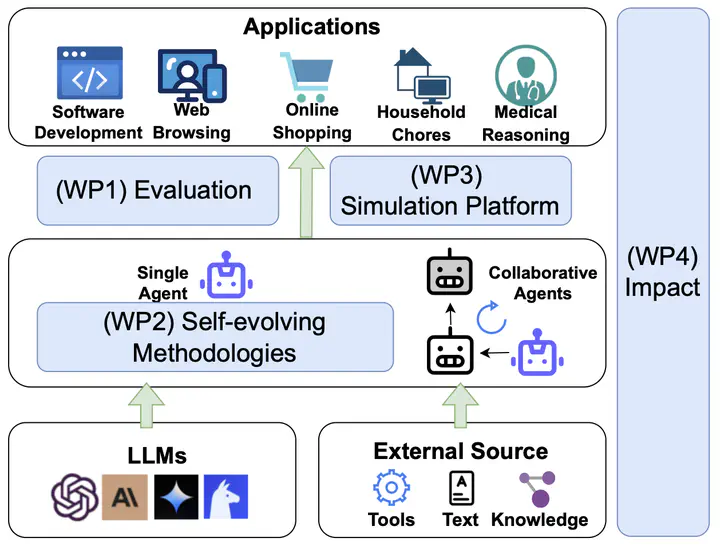
To deliver upon the three project objectives, the project is broken into four work packages (WPs):
- WP1: Automating LLM-based Agents Evaluation via Agentic Evaluator (Months 1-6)
- WP2: Research and Develop New Methodologies for Agent Self-evolution (Months 7-12)
- WP3: Developing a Versatile Simulation Platform for the Self-Evolution of Collaborative LLM-based Agents (Months 12-18)
- WP4: Public Engagement and Impact Maximization (Months 7-18)
This research proposal was originally developed for the Cooperative AI Foundation (CAIF) scheme. Although it was not selected for funding, the research agenda remains active, and we have initiated some preliminary work: EvoAgentX: https://github.com/EvoAgentX/EvoAgentX. Below are some of the latest publications and developments related to this research direction.
- Wang, Y., Liu, S., Fang, J., & Meng, Z., 2025. EvoAgentX: An automated framework for evolving agentic workflows. arXiv preprint arXiv:2507.03616.
- Zeng, R., Fang, J., Liu, S. and Meng, Z., 2024. On the Structural Memory of LLM Agents. arXiv preprint arXiv:2412.15266.
- Fang, J., Peng, Y., Zhang, X., Wang, Y., Yi, X., Zhang, G., … & Meng, Z. (2025). A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems. arXiv preprint arXiv:2508.07407.
- Liu, S., Fang, J., Zhou, H., Wang, Y. and Meng, Z., 2025. SEW: Self-Evolving Agentic Workflows for Automated Code Generation. arXiv preprint arXiv:2505.18646.
For the latest publications and developments related to this research direction, please visit my Google Scholar profile.
Zaiqiao Meng (蒙在桥)
Lecturer (Assistant Professor)
My research focuses on the intersection of machine learning, knowledge graph, and natural language processing, with a current emphasis on the biomedical applications.