Biography
I currently hold the position of Lecturer (Assistant Professor) at the University of Glasgow, within the esteemed Information Retrieval Group and IDA section of the School of Computing Science. Additionally, I serve as an Affiliated Lecturer at the Language Technology Lab (LTL) at the University of Cambridge.
Previously, I conducted research as a Postdoctoral Researcher at the Language Technology Lab (LTL) of the University of Cambridge and as a Postdoctoral Researcher at the Information Retrieval group of the University of Glasgow. I have also been a visiting PhD student at the MINE lab of KAUST.
My research topics includes, Natural Language Processing, Information Retrieval, LLMs, AI Agents, as well as Knowledge (Graphs) Extraction, Representation & Reasoning Learning, particularly within BioMedical applications (AI4Biomedicine).
I co-lead the Glasgow AI4BioMed Lab, where we work on natural language processing, knowledge graphs, language models, and more to extract and infer biomedical knowledge. If you are interested in collaborating or pursuing a PhD with us, please refer to this post and this page for more details.
I won’t be updating this website since 2025 due to laziness.
- Natural Language Processing
- AI for BioMedicine
- Information Retrieval
- Knowledge Graph
- Geometric Deep Learning
- Recommender Systems
- Machine Learning
PhD in Computer Science, 2018
Sun Yat-sen University
M.Eng. in Computer Science, 2014
Guangdong University of Technology
B.Eng. in Software Engineering, 2010
Jiangxi University of Science and Technology
Diploma in Software Technology, 2008
Jiangxi University of Science and Technology (NanChang Campus)
News
- 2025-8-20: 🥳 Three papers were accepted by EMNLP 2025 on FusionDTI for drug-target interaction, Long-Tail Biomedical Knowledge Editing, and temporal reasoning evaluation, see you in Suzhou!
- 2025-8-12: 📢 Excited to announce our new survey paper: A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems! 🌱🤖 A deep dive into techniques that bridge foundation models with lifelong agentic systems, featuring a unified framework, domain-specific strategies, and insights on evaluation, safety, and ethics. Read the full survey 👉 arXiv | Explore resources on GitHub
- 2025-5-15: 🚀 Thrilled to introduce EvoAgentX: The world’s first self-evolving framework for AI Agents!🌐 An automated framework for evaluating and evolving agentic workflows. Build and evolve your agents today at 👉 EvoAgentX
- 2025-5-15: Two papers were accepted by ACL 2025 on Knowledge-enhanced retrieval-augmented generation (RAG) models and Temporally-aware multimodal large language model tailored for chest X-ray report generation, see you in Vienna.
- 2024-11-26: Delivered a tutorial on “Integrating Knowledge Graphs and Large Language Models for Advancing Scientific Research” with Qiang Zhang and Jiaoyan Chen at Learning on Graphs Conference 2024. Recordings are avaiable at here.
- 2024-09-20: Two papers were accepted by EMNLP 2024 on RAG models with reasoning chains and position bias in large language models.
- 2024-06-10: Two papers have been accepted at Briefings in Bioinformatics, on Automatic Biochemical Pathway Prediction and Gene-disease Association Prediction.
- 2024-05-16: Two papers were accepted by ACL 2024 on Retrieval-Augmented Generation with Knowledge Graph Generation and Medical Open-Domain Question Answering.
- 2024-03-28: As the co-organization chair, we are organising the KEIR@ECIR 2024 workshop in Glasgow, UK.
- 2024-03-24: As the local organization chair, we are organising the ECIR 2024 conference in Glasgow, UK.
- 2024-01-16: Our paper entitled “CLEX: Continuous Length Extrapolation for Large Language Models” was accepted by ICLR 2024.
- 2023-12-17: Our paper entitled “BAND: Biomedical Alert News Dataset” was accepted by AAAI 2024.
- 2023-12-10: Invited to serve as one of the Area Chairs for NAACL 2024.
- 2023-10-9: Two papers were accepted by EMNLP 2023 on Unsupervised Biomedical NER and Multimodal Generative Language Model.
- 2023-09-26: Our survey paper on Knowledge Graph Embedding was accepted by ACM Computing Surveys.
- 2023-08-14: Our survey paper on Multimodal Language Modelling was accepted by ACM Transactions on Multimedia Computing, Communications, and Applications
- 2023-08-05: One paper was accepted by CIKM 2023 on Knowledge-enhance Passage Ranking.
- 2023-06-26: Invited to serve as one of the Area Chairs for the track “Interpretability, Interactivity and Analysis of Models for NLP” of EMNLP 2023.
- 2023-06-09: I gave an invited talk on “Probing and Infusing Biomedical Knowledge for Pre-trained Language Models” in “NLP for Social Good (NSG) Symposium 2023” hosted by Dr Procheta Sen at the University of Liverpool.
- 2023-05-22: One paper was accepted by Matching ACL 2023 on Generative Event Extraction.
- 2023-05-02: One paper was accepted by ACL 2023 on Few-shot NER.
- 2023-03-02: One paper was accepted by Transactions on the Web (TWEB) on Conversational Recommendation Systems.
- 2023-02-10: I gave a guest lecture on “Words Sense and WordNet” for the “LI18 - Computational Linguistics” course offered by Professor Nigel Collier at the University of Cambridge.
- 2023-01-24: I am an Area Chair for the “Interpretability and Analysis of Models for NLP” track of ACL 2023.
- 2023-01-21: One paper was accepted by EACL 2023 on Deductive Reasoning Analysis of Pretrained models. The preprint of it can be found in this link.
- 2022-10-25: I will be attending EMNLP 2022 (Abu Dhabi, UAE 🇦🇪) in person.
- 2022-10-06: One paper was accepted by EMNLP 2022 on Parameter-Efficient Tuning.
- 2022-10-04: Our paper entitled Graph Neural Pre-training for Recommendation with Side Information was accepted at ACM TOIS.
Current Members
Auss Abbood
University of Cambridge
PhD student (2024.10 - )
Jiaming Yang
University of Glasgow
PhD student (2024.4 - )
Jinyuan Fang
University of Glasgow
PhD student (2022.11 - )
Meiru Zhang
University of Cambridge
PhD student (2021.10 - )
Shen Dong
University of Glasgow
PhD student (2024.01 - )
Susmita Das
University of Glasgow
PhD student (2024.11 - )
Wei Sun
University of Glasgow
PhD student (2024.10 - )
Xi Zhang
University of Glasgow
PhD student (2023.10 - )
Xinhao Yi
University of Glasgow
PhD student (2023.10 - )
Xuejun Chang
University of Glasgow
PhD student (2024.10 - )
Zhaohan Meng
University of Glasgow
PhD student (2023.10 - )
Alumni
Adam Fairlie
University of Glasgow
BSc/MSc student (2022.09 - 2023.01)
Francesco Dalla Serra
University of Glasgow
PhD student (2023.10 - 2024.11) Now researcher at Canon Medical Research Europe
Gan Wang
University of Glasgow
PhD student (2023.10 - 2024.10)
Giacomo Frisoni
University of Bologna
Visiting PhD (2022.9 - 2022.12) Now Researcher at University of Bologna
Guanzhen Chen
Sun Yat-sen University
Research Intern (2022.June - 2022.Sep) Now PhD at National University of Singapore
Tanatapanun (Mark) Pongkemmanun
University of Glasgow
BSc student & RA (2023.7 - 2024.8) now MSc at University of Glasgow
Varsha Joshy
University of Glasgow
BSc/MSc student (2022.6 - 2022.9) Now Senior Software Engineer at JPMC
William Traynor
University of Glasgow
BSc/MSc student (2022.10 - 2023.9) Now Research & Development Graduate at Canon Medical Research Europe
Xinhao Yi
University of Glasgow
BSc/MSc student (2022.6 - 2023.10) Now PhD at University of Glasgow
Zhaohan Meng
University of Glasgow
BSc/MSc student (2022.7 - 2023.10) Now PhD at University of Glasgow
Projects

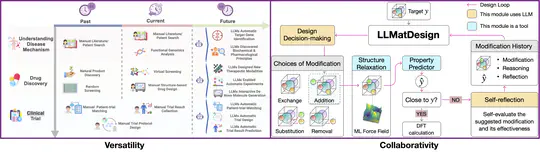
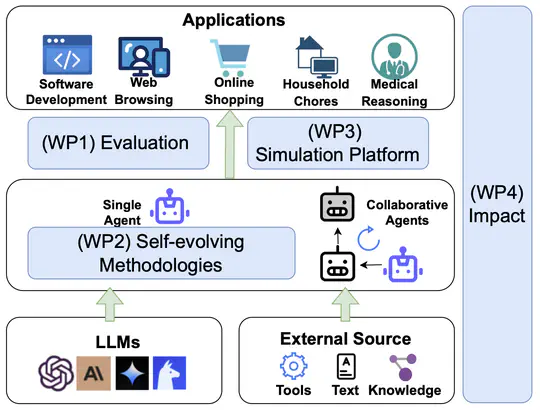


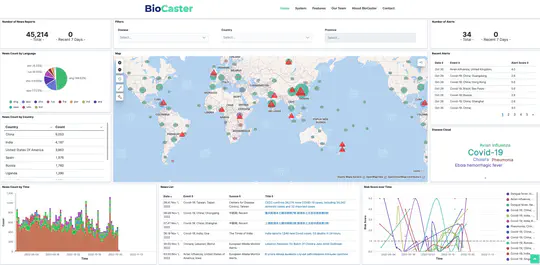
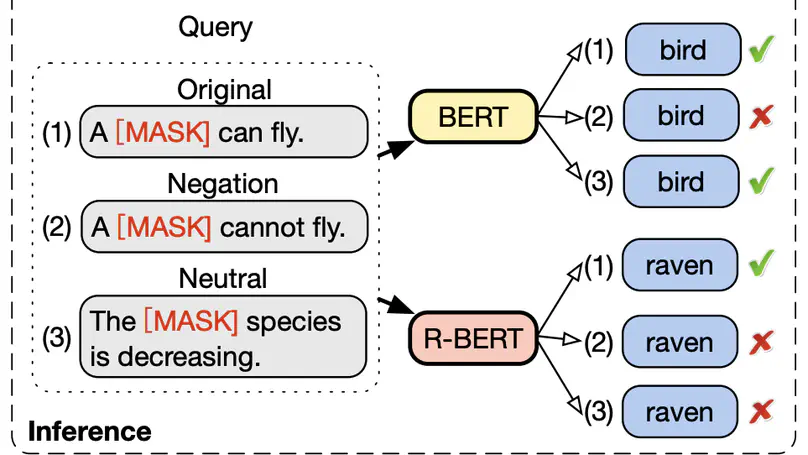
Featured Publications
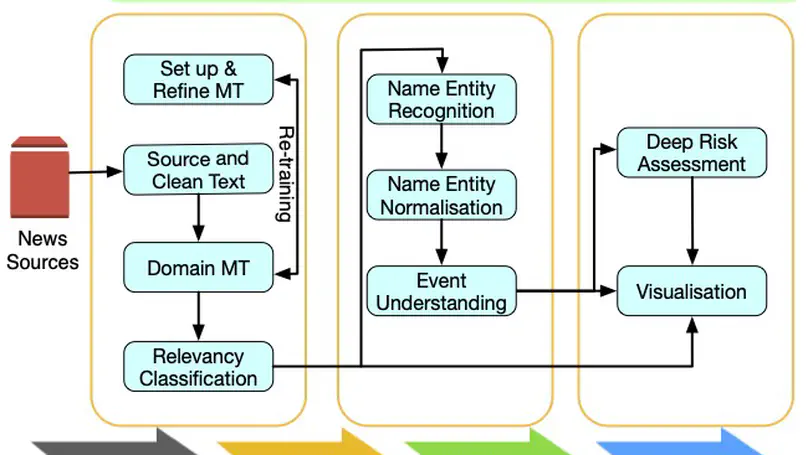
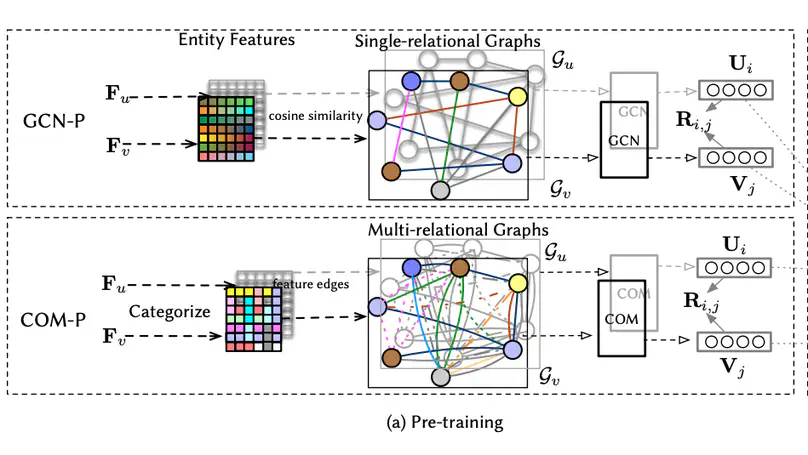
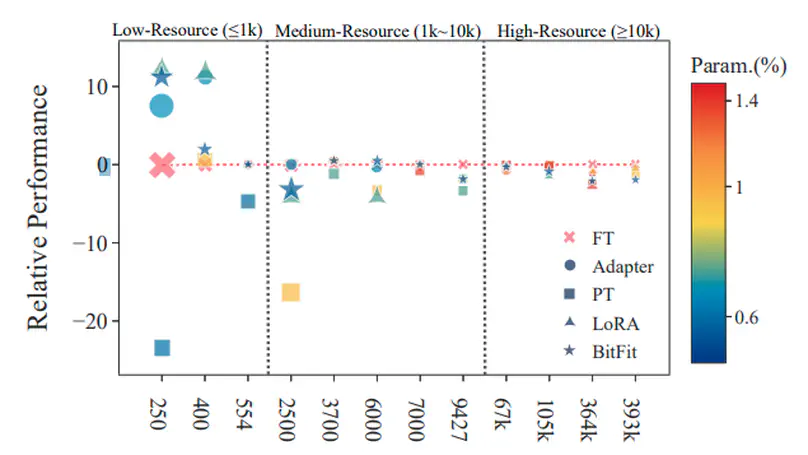
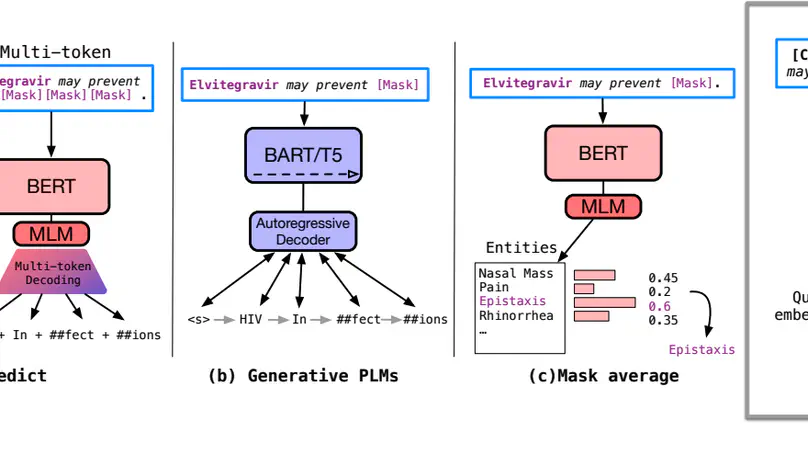
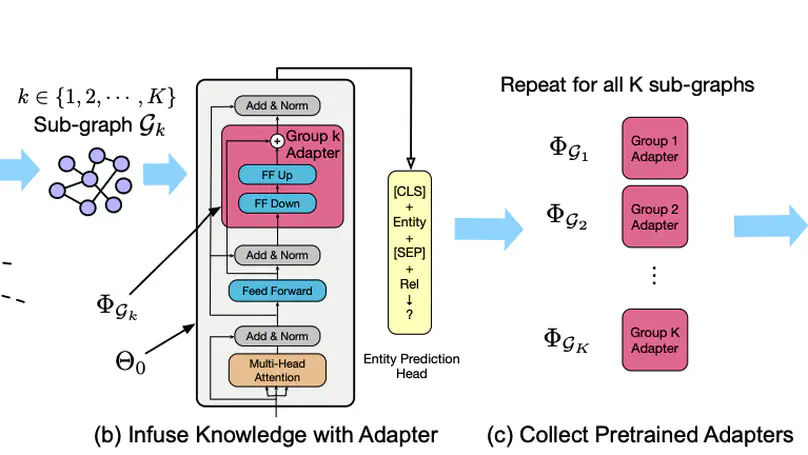
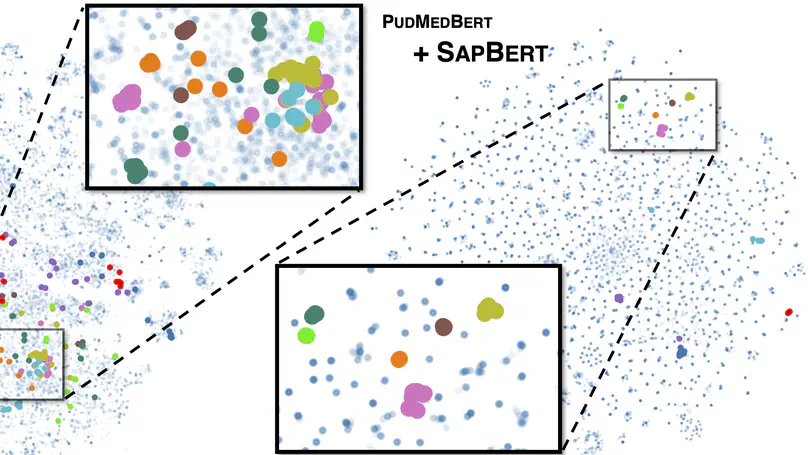
Professional Service
Conference/Workshop Organisers:
- The European Conference on Information Retrieval (ECIR) 2024, Local Organisation Chair
- The First Workshop on Knowledge-Enhanced Information Retrieval workshop (KEIR @ ECIR 2024), Workshop Chair
Conference Area Chair/Senior Program Committee:
- The Annual Meeting of the Association for Computational Linguistics (ACL), 2023
- The Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
Conference Program Committee/Reviewer:
- Conference On Language Modeling (COLM), 2024
- International Conference on Machine Learning (ICML), 2021, 2022, 2023, 2024
- The Conference on Neural Information Processing Systems (NeurIPS), 2020, 2021, 2022, 2023, 2024
- The International Conference on Learning Representations (ICLR), 2021, 2022, 2023, 2024
- The Annual Meeting of the Association for Computational Linguistics (ACL), 2022, 2023, 2024
- ACL Rolling Review, 2021, 2022, 2023, 2024
- The Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018, 2021, 2022
- The 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2023
- The ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2018, 2021, 2022, 2023, 2024
- The Conference on Information and Knowledge Management (CIKM), 2017, 2018
- The ACM Conference on Web Search and Data Mining (WSDM), 2018, 2019
- The European Conference on Information Retrieval (ECIR), 2020, 2021, 2022, 2023, 2024
- The ACM Web Conference (WWW), 2018, 2021, 2022, 2023,2024
- The ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD), 2021, 2022
- The AAAI Conference on Artificial Intelligence (AAAI), 2020, 2021, 2022, 2023, 2024
- The ACM Recommender Systems Conference (RecSys), 2020, 2021, 2022
- International Joint Conference on Artificial Intelligence (IJCAI), 2018, 2020, 2022
- The SIAM International Conference on Data Mining (SDM), 2022
Journal Editor/Guest Editor:
- Special Issue of Electronics (ISSN 2079-9292) journal on “Natural Language Processing and Information Retrieval”.
Journal Invited Reviewer:
- ACM Transactions on Information Systems
- ACM Transactions on the Web
- ACM Computing Surveys
- Information Retrieval Journal
- ACM Transactions on Recommender Systems
- Computers in Biology and Medicine
- IEEE Transactions on Knowledge and Data Engineering
- IEEE Transactions on Neural Networks and Learning Systems
- IEEE Transactions on Cybernetics
- Information Sciences
- World Wide Web
- IEEE Transactions on Fuzzy Systems
- IEEE Access
- International Journal of Machine Learning and Cybernetics
- Concurrency and Computation: Practice and Experience
Teaching
Contact
- zaiqiao.meng@glasgow.ac.uk
- 220b Sir Alwyn Williams Building, Glasgow, UK, G128QQ
-
Monday 09:00 to 18:00
Friday 09:00 to 18:00 - Follow Me